Learning General World Models in a Handful of Reward-free Deployments
Learning General World Models in a Handful of Reward-Free Deployments
Yingchen Xu*
(UCL, FAIR)
Jack Parker-Holder*
(Oxford)
Aldo Pacchiano*
(MSR)
Phillip J. Ball*
(Oxford)
Oleh Rybkin
(UPenn)
Stephen J. Roberts
(Oxford)
Tim Rocktäschel
(UCL)
Edward Grefenstette
(UCL, Cohere)
(UCL, FAIR)
(Oxford)
(MSR)
(Oxford)
(UPenn)
(Oxford)
(UCL)
(UCL, Cohere)
NeurIPS 2022
Abstract
Building generally capable agents is a grand challenge for deep reinforcement learning (RL). To approach this challenge practically, we outline two key desiderata: 1) to facilitate generalization, exploration should be task agnostic; 2) to facilitate scalability, exploration policies should collect large quantities of data without costly centralized retraining. Combining these two properties, we introduce the reward-free deployment efficiency setting, a new paradigm for RL research. We then present CASCADE, a novel approach for self-supervised exploration in this new setting. CASCADE seeks to learn a world model by collecting data with a population of agents, using an information theoretic objective inspired by Bayesian Active Learning. CASCADE achieves this by specifically maximizing the diversity of trajectories sampled by the population through a novel cascading objective. We show a tabular version of CASCADE theoretically improves upon naïve approaches that do not account for population diversity. We then demonstrate that CASCADE collects diverse task-agnostic datasets and learns agents that generalize zero-shot to novel, unseen downstream tasks on Atari, MiniGrid and the DM Control Suite.
Reward-Free Deployment Efficiency
Goal: Train generalist agents at scale.
-
To make agents general, we want to collect reward-free data. This makes it possible to solve a wide variety of tasks which may have different reward functions.
-
To make our methods scale, we want to collect data in parallel and update our policy infrequently.
Current methods: Plan2Explore trains the exploration policy online, updating every timestep. It has generality but not scalability.
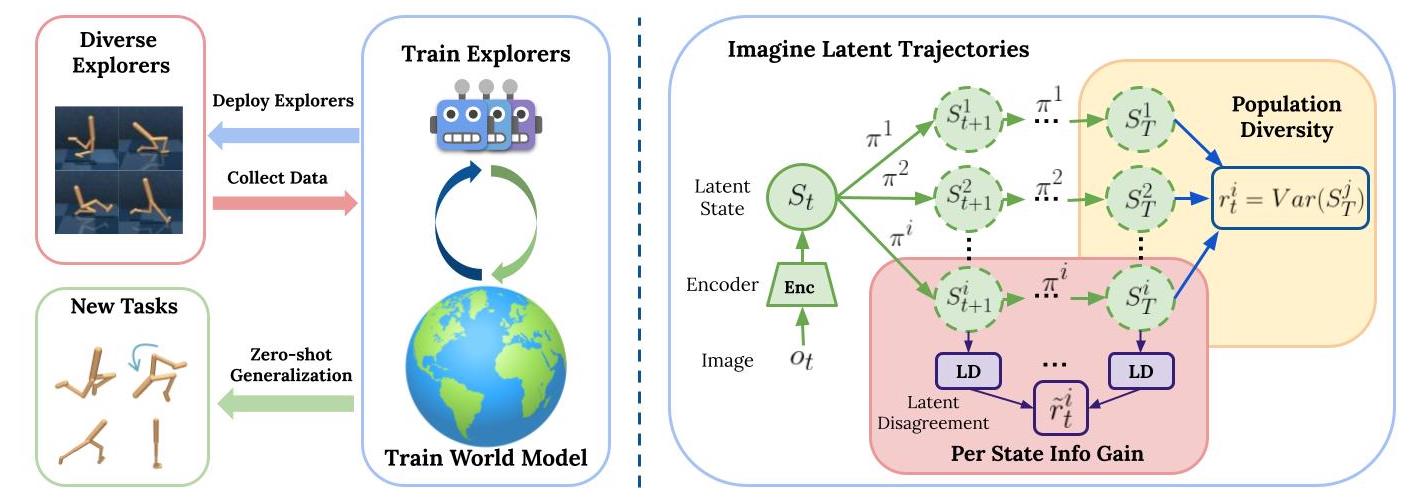
Coordinated Active Sample Collection via Diverse Explorers
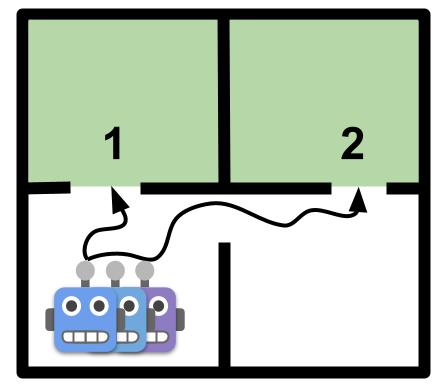 Imagine that we want to learn a model of a room. Green areas represent high expected information gain. A population of independently trained agents will likely all follow the trajectory to #1 at deployment.
Imagine that we want to learn a model of a room. Green areas represent high expected information gain. A population of independently trained agents will likely all follow the trajectory to #1 at deployment.
To avoid collecting a homogenous dataset in such cases, CASCADE trains agents by taking into account the population diversity, in addition to the information gain, and thus encourages each individual agent to sample states that maximally improve the world model.
Data Diveristy
Each row below visualizes data collected by a population of explorers trained by the same world model, deployed at the same time in the same environment.
We can see that CASCADE explorers display much more diverse useful behaviors than Plan2Explore agents (trained without considering population diversity).
CASCADE

Plan2Explore (without population diversity)

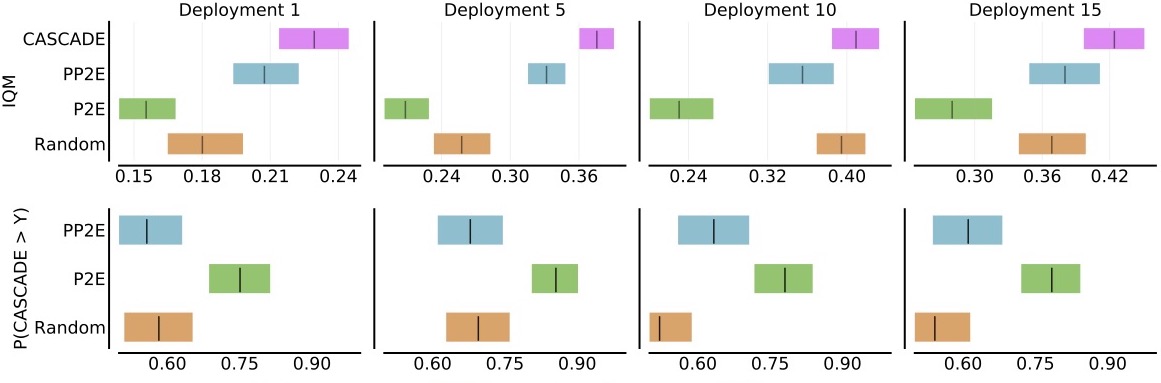
Zero-shot Performance
We test whether the learned world models are general enough to facilitate learning downstream policies for previously unknown tasks in a zero-shot fashion as follows:
- We provide reward labels to the world model;
- We train a separate reward head;
- We train a task specific behavior policy and test it in the environment.
Walker
Aggregated over four unseen tasks (stand, walk, run, flip).
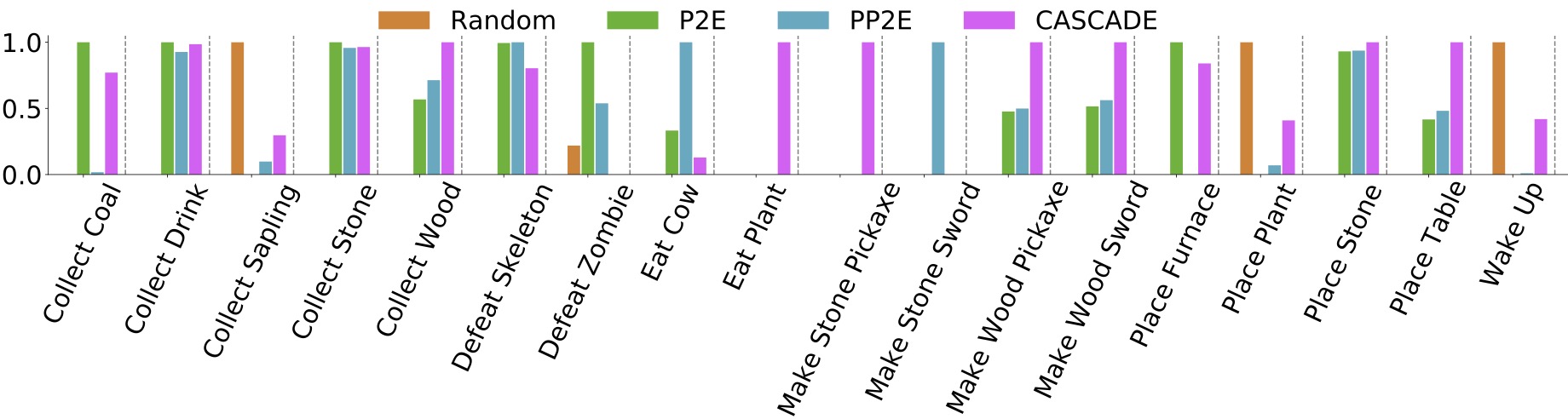
Atari & Crafter
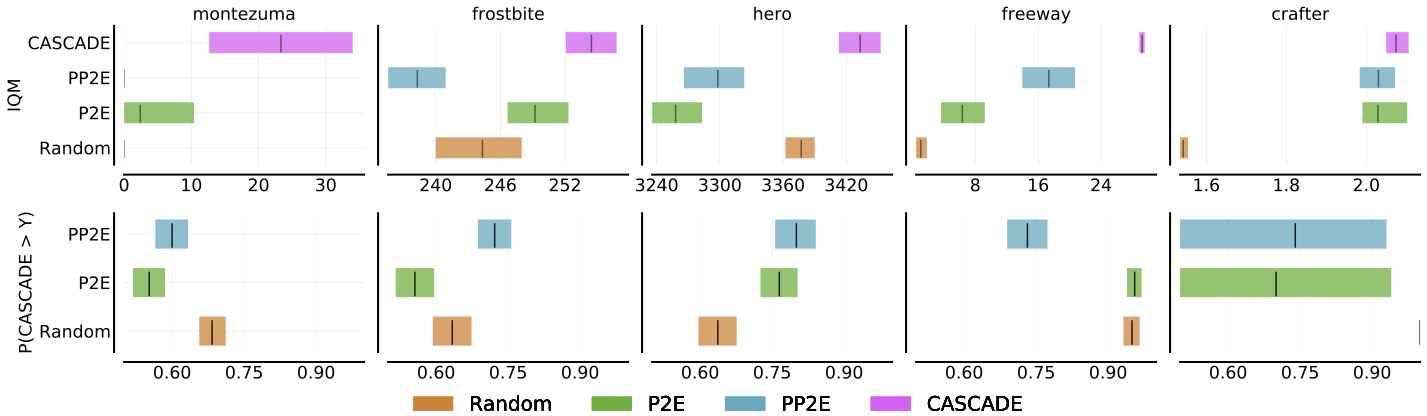
Crafter Normalized Skill Success Rate
Note that CASCADE not only achieves the highest average success rate but also unlocks the most (16 out of 22) unique skills among all baselines.