Humanoid Control with a Generalist Planner
H-GAP: Humanoid Control with
a Generalist Planner
Zhengyao Jiang*
(UCL)
Yingchen Xu*
(UCL, FAIR at Meta)
Nolan Wagener
(Georgia Tech)
Yicheng Luo
(UCL)
Michael Janner
(UC Berkeley)
Edward Grefenstette
(UCL)
Tim Rocktäschel
(UCL)
Yuandong Tian
(FAIR at Meta)
(UCL)
(UCL, FAIR at Meta)
(Georgia Tech)
(UCL)
(UC Berkeley)
(UCL)
(UCL)
(FAIR at Meta)
 ICLR 2024 Spotlight
ICLR 2024 Spotlight
![[Poster]](/images/h_gap_better_54_x_36_iclr.png){kind=link}
We present Humanoid Generalist Autoencoding Planner (H-GAP), a state-action trajectory generative model trained on humanoid trajectories derived from human motion-captured data, capable of adeptly handling downstream control tasks with Model Predictive Control (MPC). For 56 degrees of freedom humanoid, we empirically demonstrate that H-GAP learns to represent and generate a wide range of motor behaviours. Further, without any learning from online interactions, it can also flexibly transfer these behaviors to solve novel downstream control tasks via planning. Notably, H-GAP excels established MPC baselines that have access to the ground truth dynamics model, and is superior or comparable to offline RL methods trained for individual tasks. Finally, we do a series of empirical studies on the scaling properties of H-GAP, showing the potential for performance gains via additional data but not computing.
H-GAP Overview
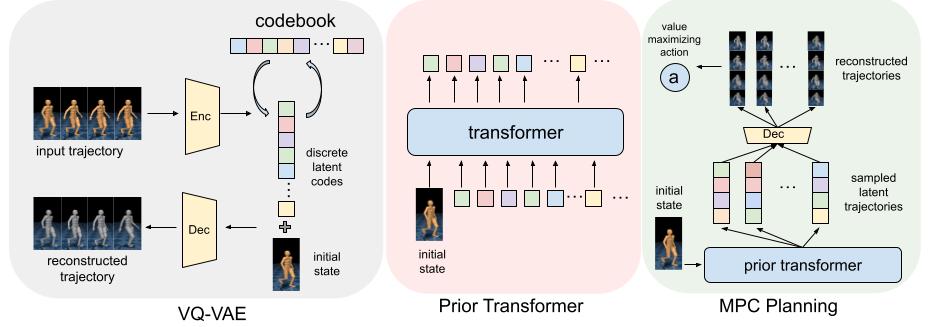
Left: A VQ-VAE that discretizes continuous state-action trajectories.
Middle: A Transformer that autoregressively models the prior distribution over latent codes, conditioned on the initial state.
Right: Zero-shot adapation to novel tasks via MPC planning with learned Prior Transformer, underscoring H-GAP’s versatility as a generalist model.
Imitation Learning
We train H-GAP on MoCapAct dataset, which contains over 500k rollouts displaying various motion from the CMU MoCap dataset. Starting from the same state, H-GAP with greedy decoding can recover the various behaviours from the reference clips. Note that action noise is added to the final output of H-GAP, so the imitation can’t be achieved by just memorisation.
Walking
(CMU-002-01)
 Backwards
Backwards
CMU-041-02)
 Long Jumping
Long Jumping
(CMU-013-11)

Jumping Jack
(CMU-014-06)
 Cart Wheeling
Cart Wheeling
(CMU-049-07)
 Turning
Turning
(CMU-010-04)

(CMU-002-01)
CMU-041-02)
(CMU-013-11)
(CMU-014-06)
(CMU-049-07)
(CMU-010-04)
The reference snippets are short, but H-GAP with greedy decoding can continue the behaviours after reference snippets, sometimes forming a closed loop.
Turning
 Raise hand
Raise hand
 Shifting
Shifting

Downstream Control
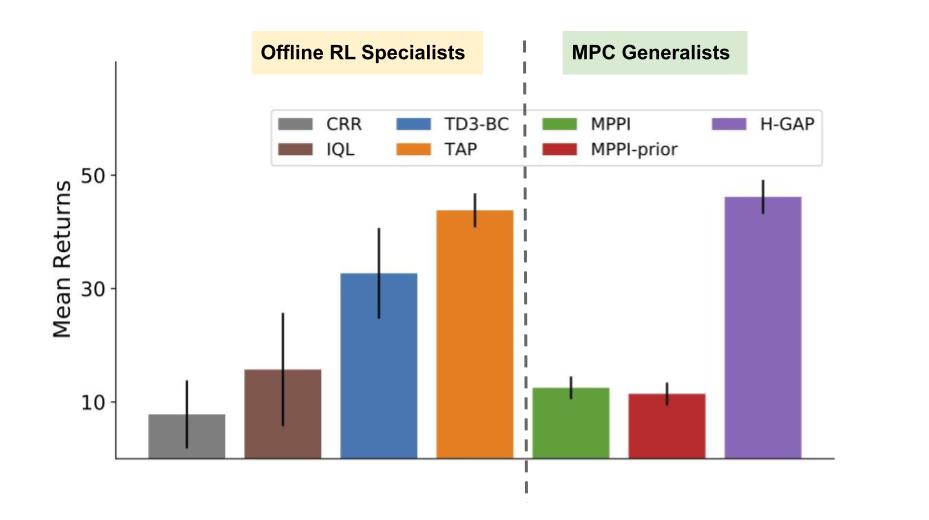
To test H-GAP’s zero-shot control performance as a generalist model, we design a suite of six control tasks: speed, forward, backward, shift left, rotate and jump. H-GAP matches or beats offline RL methods trained individually for each task. It also outperforms MPC with access to true dynamics, showing benefits of learned action space.
H-GAP with MPC planning can achieve sensible performance on a wide range of downstream tasks in a zero-shot fashion. Starting from an initial state that is irrelevant or contradictory to the objective, the agent will have to figure out a proper transition between motor skills. For example, it may start with a forward motion when the task is to move backwards.
 Speed
Speed


 Rotate
Rotate


 Jump
Jump


 Forward
Forward


 Shift Left
Shift Left


 Backwards
Backwards

